可变形卷积代码篇
一个调用 from mmcv.ops import ModulatedDeformConv2d 的例子:
def forward(self, input):
x = self.offset_mask_conv(input)
o1, o2, mask = torch.chunk(x, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
output = self.dcnv2(input, offset, mask)
return output
总而言之 offset 的 size 就是 2*kernel[0]*kernel[1] ,想一想,原来我们求偏移的时候,会把 B*H*W*C 的图像送入普通卷积得到 B*H*W*2C 得到偏移,也就是每个通道每个位置点都有 x 和 y 两个方向的偏移量。
对 DCN 来说,每个通道都做一样的处理,也就是只需要对每个位置点存卷积核每个点的 x 和 y 的偏移,所以就是 B*H*W*(2*kernel_size) 。
关于 mask::置信 mask,并非必需,不作展开了
所以 offset 和 mask 一起就是 B*H*W*(3*kernel_size)
关于 deform_groups:本来是所有通道公用,也可以改成划成几组,组数就是 deform_groups,那这样就是 B*H*W*(group_num*3*kernel_size)
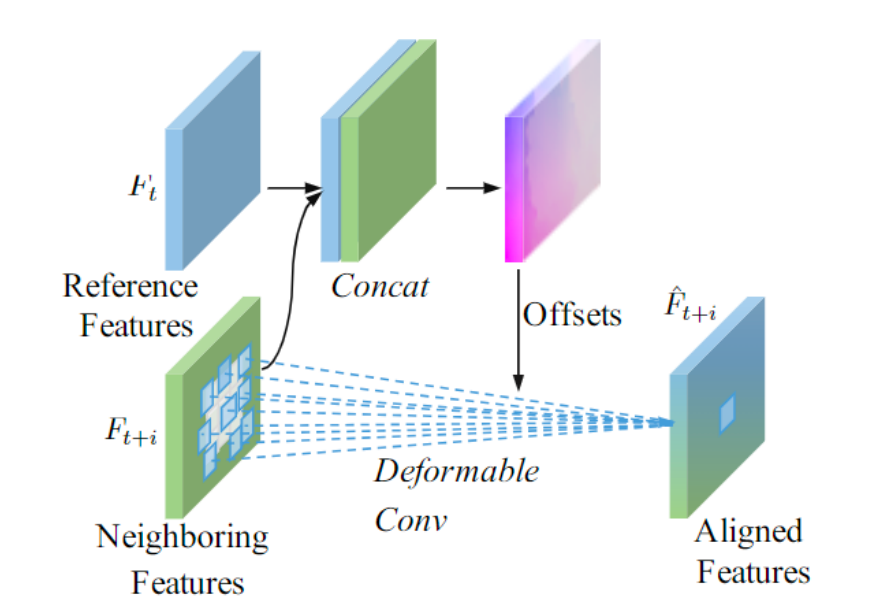
可变形卷积与光流
端到端视频压缩模型里,运动估计运动补偿环节,常用到光流和可变形卷积。本质上都是预测偏移,只不过 DCN 可以利用多个偏移,这样在预测难度较大的位置就有多个 offset 互作补充,所以比只用单一的光流更有优势一些。
推荐一下这篇文章:Understanding Deformable Alignment in Video Super-Resolution,讲得比较透彻了。
可变形卷积涉及多少个不同的 offset map
-
首先,与 kernel size 有关
假设特征图大小为
W * H,每个点的感受野都对应了kernel_size * kernel_size个偏移 -
其次,与 group num 有关

每
C(通道数) / group_num个通道共用一套 offset比如假设特征有 8 个通道,group_num 为 4,则 每 2 个通道共用一套偏移参数
综合来说,一共会有 (kernel_size * kernel_size) * group_num 个 W * H 大小的偏移图。
DCN 对齐和光流对齐的本质差异
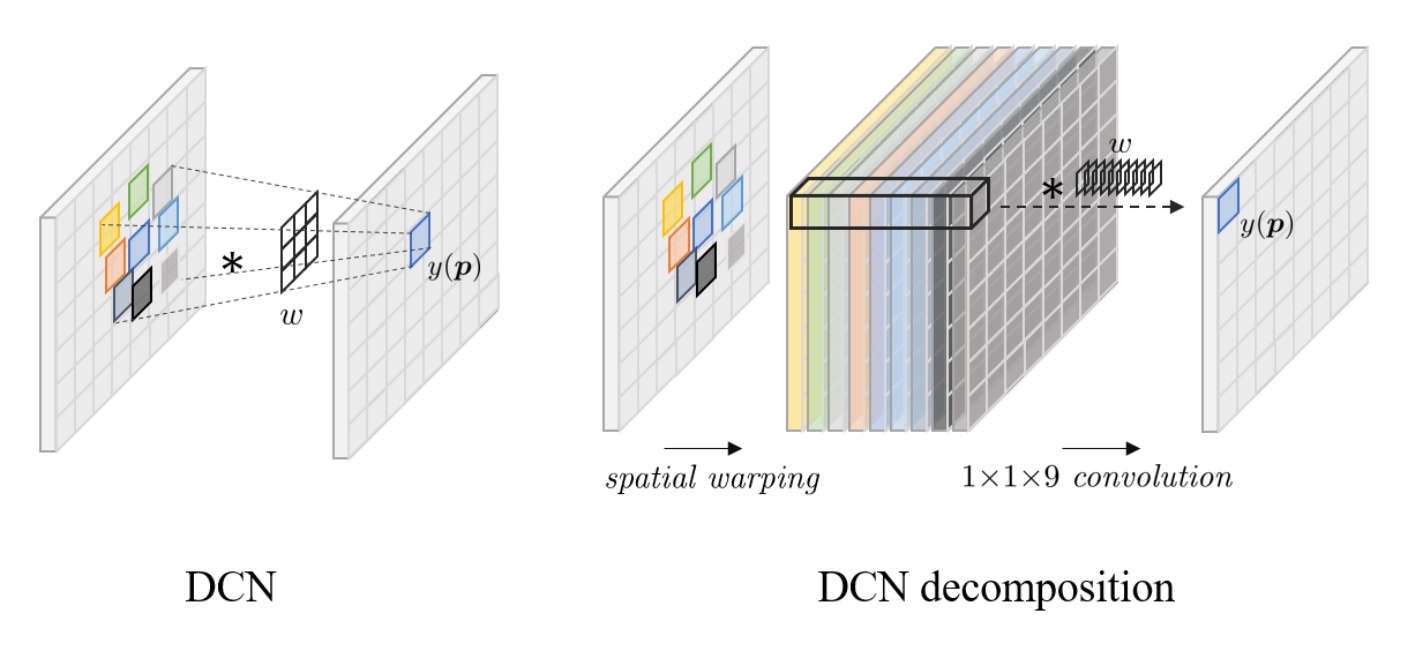
$kernel \space size 为 n * n的DCN = n^2个空间warping \space +\space 1 * 1 * n^2 的3D卷积$
也就是说,如果 n=1,group_num=1,DCN对齐基本就等同于光流对齐,DCN 和光流的本质区别就在于 offset diversity。
最后修改于 2022-02-20