dispatcher: gives control of the CPU to the process selected by the short-term scheduler;
dispatch latency
scheduling criteria
-
CPU utilization,
-
throughput:
单位时间完成进程数量
-
turnaround time:
submission to completion
-
waiting time:
sum of time spent in the ready queue就绪队列
-
response time:
submission to first response(time it takes to start responding, not the time it takes to output the response)
scheduling algorithm
-
FCFS first-come, first-served
non-preemptive
等待时间较长
convoy effect(短进程跟在长进程后面)
-
SJF shortest-job-first
shortest next CPU burst
常用于长期调度,短期调度可预测next CPU burst
-
exponential average
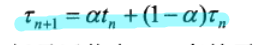
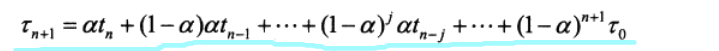
preemptive/non-preemptive
preemptive SJF : shortest-remaining-time-first scheduling
-
-
priority scheduling algorithm
SJF is a special case of it
priority can be defined internally or externally
preemptive/non-preemptive(非抢占优先级调度只是将优先级高的新进程加到ready queue的头部)
主要问题是indefinite blocking/starvation
低优先级无穷等待问题解决方法: aging(逐渐增加等待很久进程的优先级)
-
RR round-robin
especially for time-sharing system
时间片(time quantum/time slice)
所需时间小,自动释放CPU,所需时间大,时间片到timer会产生中断
平均等待时间较长
preemptive

时间片很大:FCFS;时间片很小:processor sharing(仿佛都有自己的处理器,速度为1/n)
时间片应比context-switch time大,也不应太大
-
multilevel queue scheduling algorithm
foreground(interactive); background(batch) 前台进程更高优先级。前台可能RR,后台可能FCFS
ready queue划分成多个队列,一个进程被永久分配到一个队列,每个队列有自己的调度算法
队列间常采用fixed-priority preemptive scheduling, 或在队列间划分时间片,每个队列有一定CPU时间
-
multilevel feedback queue schedling algorithm
允许进程在队列之间移动
使用过多CPU时间,移到低优先级队列。所以IO bound & interactive processes(使用CPU时间少)会被留在高优先级队列
较低优先级队列等待时间过长的进程也会被转移到更高优先级队列,prevent starvation
看例子P172最通用的CPU调度算法
-
HRRN highest response-ratio next 高响应比优先
non-preemptive
PPT P51
multi-processor scheduling
非对称多处理(asymmetric multiprocessing),一个处理器处理调度,IO,其他系统活动;其余处理器处理用户代码
SMP symmetric multiprocessing 对称多处理:每个处理器自我调度,许多OS支持SMP
processor affinity: 使缓存无效或重构的代价太高,所以尽量使一个进程在同一个处理器上允许。不能保证进程不移动:soft affinity,否则hard affinity
load balancing: 将工作负载平均地分配到SMP所有处理器上。load balancing只对拥有自己私有可执行进程的处理器必要(大部分时候都有私有)
push migration: a specific task周期检查每个处理器上的负载,如果不平衡,push processes from overloaded to idle processor
pull migration: an idle processor pulls a waiting task from a busy processor
multicore processors: PPT P61

SMT: symmetric multithreading 提供多个逻辑处理器实现多线程并发 hyperthreading. 每个逻辑处理器负责自己的中断处理。
thread scheduling
对在内核级支持线程的系统而言,系统调度的是内核线程而不是进程。用户线程由线程库管理。
PCS: process-contention-scope 线程库调度用户级线程到一个有效的LWP上(CPU竞争发生在属于相同进程的线程之间) ,local scheduling
SCS: system-contention-scope 调度哪个内核线程到CPU(CPU竞争发生在系统的所有线程中)。一对一模型只用使用SCS ,global scheduling
实例 书P178
algorithm evaluation
analytic evaluation: 产生一个公式或数字
deterministic evaluation: 计算在给定负荷下算法的性能
queueing-network-analysis:

simulation模拟 trace tape
最后修改于 2020-02-28